Can happen…hardware is not forever so a fail is behind the corner. When this happen to a hypervisor node is not funny and can create panic to IT department. If the procedure to replace a server/disk is easy when the task is scheduled, there’s an halo of mistery when this happen unexpectly.
In my case, one of my node Azure Stack HCI fails but after replaced the failed OS disks and reinstalled the Operating System, I found a little issues to re-join the storage side into the Cluster Storage Pool. All disks of “new” server are in Transient Error even are cleaned to avoid issues during rejoin.
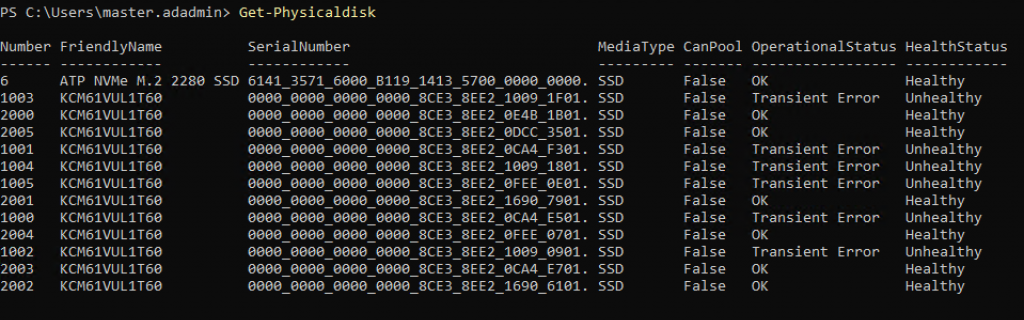
The Virtual Disk was in Degraded State because was not able to replicate files between nodes.
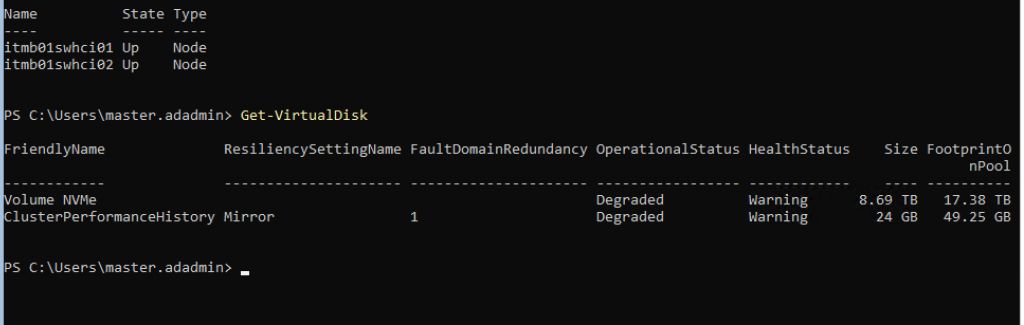
From the cluster prospective, everything was ok because the VM running without problem but in Redirection Mode (when a node use the disks of another node via LAN).
The Fix
After several test, I found the solution with these cmdlets.
Note: make sure you have a good backup of your VMs before running this steps.
- Get-PhysicalDisk -> detect the ID of your disks in Error
- Update-StorageProviderCache -DiscoveryLevel Full
- Get-PhysicalDisk | ? {$_.deviceid -eq 1001} | Reset-PhysicalDisk -> repeat this command for all disks in error
Wait 5 minutes and run again the cmdlet Update-StorageProviderCache -DiscoveryLevel Full
Use this command to monitor the status of the disks, this might take some time to fix the issue: Get-PhysicalDisk | sort deviceid | ft deviceid,size,virt*,usage,oper*
Wait at least 12 hours, depends by your storage volume and the amount data to synchronize, before restart nodes or make other activities.
Finalize the task with storage optimization with this cmdlet:
$UniqueId = (Get-StoragePool | Where { $_.IsPrimordial -eq $false }).UniqueId
Optimize-StoragePool -UniqueId $UniqueIdSo…there’s always a solution…sometimes is not documented but this is the reason why there are the MVPs.
DBS