
Questo articolo è disponibile anche in lingua italiana al seguente link: Veeam Backup for Microsoft 365: utilizzare gli object storage – WindowServer.it
That the backup of Microsoft 365, or Office 365 if you prefer, is mandatory, it is not just a matter of self-love, or for your company, but the GDPR requires it and Microsoft itself says it, which strongly advises to protect the own data as it is the property of the customer.
And let’s be clear, we’ve been backing up our infrastructure for years because we’re worried about deletions, viruses and human errors. The fact that our workload has moved to the cloud does not eliminate the problems of the past… indeed, they probably amplify them.
There are basically 3 ways to protect Microsoft 365:
- Use a fully vendor-supplied solution
- Use a solution installed on a local server
- Use a solution installed on a cloud server
The second option seems a bit counterintuitive because if the idea of the cloud is to optimize local costs and offload the cost of storage, bringing everything back home makes no sense. The best, personally, is the third because it gives you the correct flexibility and allows you to harness the power of the cloud.
However, the cloud is not free and as resources increase the cost can go up and especially if objects designed for cost optimization are not used … such as storage.
Veeam Backup for Microsoft 365 allows you to make backups within an Object Storage Repository which allows, unlike a disk connected to the VM, to significantly reduce costs and to better manage the retention and growth policy.
In this article we will see how to configure this scenario within Microsoft Azure.
Pre-Analysis
Before starting with this scenario, it is good to understand why to turn to this type of choice. When the data is very few, with a limited growth rate, it is also possible to stay on the DAS model (the classic disk connected to the VM) but when this value increases significantly, changing the model towards Object Storage becomes a more option. that valid.
A Standard HDD, with 1TB, costs about 40 euros/month, and does not guarantee a good IOPS especially when the data starts to be a lot – and this thing is especially noticeable in the restore phase. A Hot Storage costs less than 30 euros/month for the same cut, but performs better.
So might it make sense to switch to the storage model right away? As mentioned, it must be evaluated but it is certainly interesting.
Configuration
The first thing to create is a Container within a Storage Account.
The next step is to configure the storage within Veeam Backup, of the OSR type.
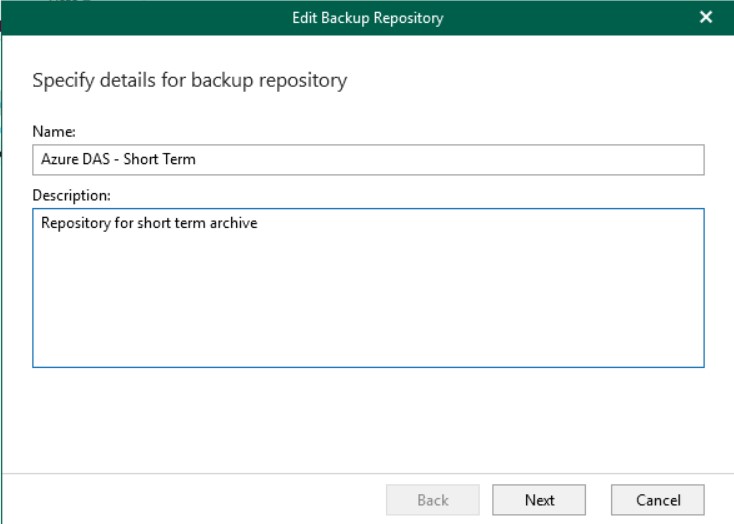
Supported storage objects are as follows: Amazon Web Services (AWS) S3, Azure Blob, IBM Cloud, Wasabi and other S3 compatible providers.

V6 introduces backup copy to Amazon Simple Storage Service (Amazon S3) Glacier, Glacier Deep Archive, and Azure Archive.

Select Azure Blob Storage, which will be used as the repository for the normal backup copy. If you want to use a “deposit” repository for long-term backups (useful when talking about environments where very high retention is required), you can also combine the Azure Archive Storage option which, however, cannot be used as primary storage.
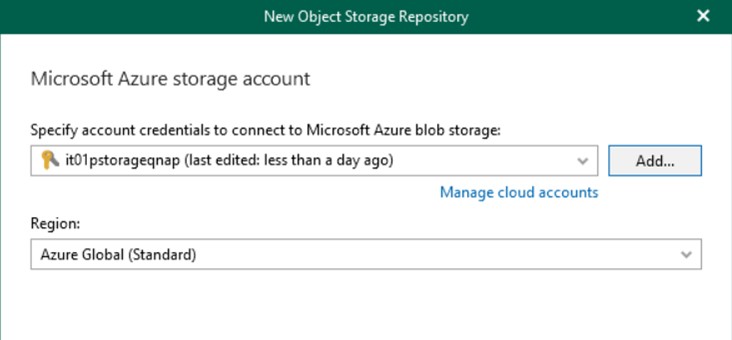
Enter the login credentials for the Azure Storage Account and create a new folder within the container initially created. It is not possible to write data inside the $root of the Container because it is not supported by Veeam Backup.
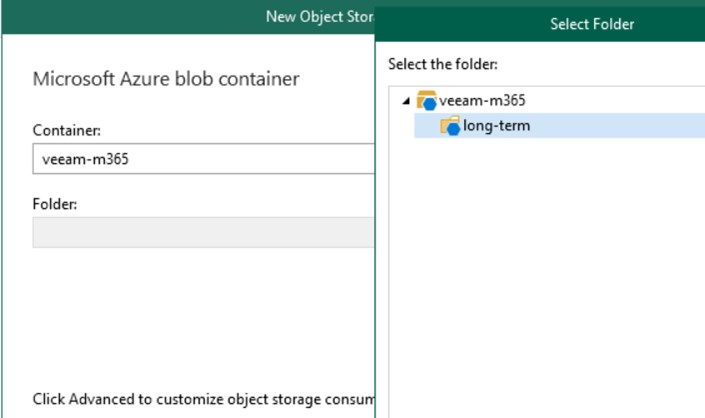
Create a new backup repository using the local disk, which is required for creating the backup metadata. This disk should be Premium SSD, even of small size but with many IOPS, to ensure a high response in case of restore.
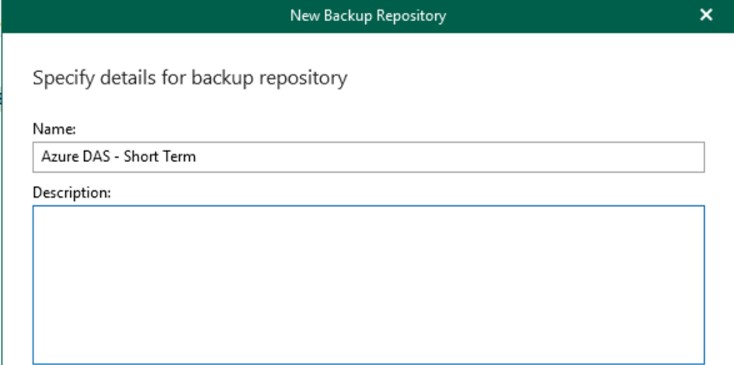
During the wizard, and only at this stage, it will be possible to set the integration with Object Storage.
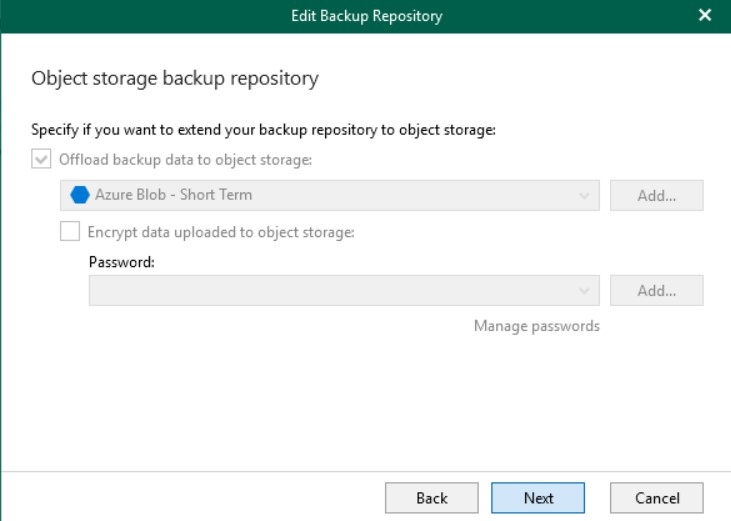
With this configuration, Veeam will store a local cache on the backup server, but will push all backup data directly to the object storage which in this case is Azure.
The persistent cache located on the server is useful when using Veeam Explorer to open the backups located in the object storage, improving search performance. The cache contains metadata information about backed up objects and is created (or updated) during each backup session. This is why Premium SSD disk is suggested.
When selecting an Object Storage as the repository, all data will be compressed and backed up directly to the object store; in addition, the cache will also be saved in the extended backup repository for consistency reasons.
Backup
If you start from scratch it’s all easy, but if the idea is to replace a DAS repository, then you need to understand where to place the files from previous backups because it is possible that what will be the new repository will not have deleted objects inside. previously and therefore present in the “old” backup job.
This poses a potential problem if a file/mail/item should be recovered. It depends on the type of company and requirements, but you can think of leaving the log in the DAS repository or moving it to an Object Storage but this means having to download it in full to make a possible restore.
Performance and Parallelisms
When you start from scratch, or you have to protect many objects, both in quantity and weight, it may be necessary to have important performances in your virtual machine. Veeam requires at least 4CPU and 8GB of memory but this value may be lower than required. Above 40k objects, or with more than 2TB of SharePoint documents, 8CPUs and 16GB of memory are required because the use of the Proxy Agent is prominent.
To stem the continuous use of resources, it is necessary to reduce the number of parallelisms managed by the Proxy Server from 64 to 32.
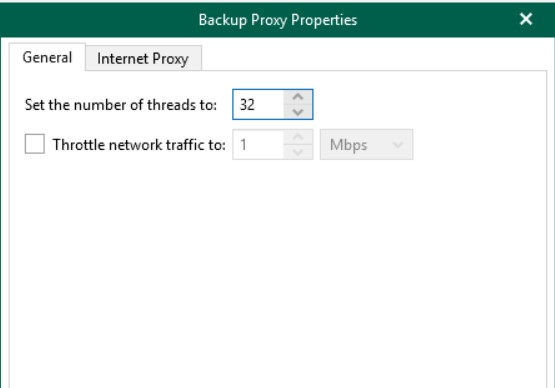
Once the first backup cycle has finished, it will be possible to reduce the performance of the VM, leaving the threads unchanged, because the differentials are less impacting. However, this is true only if there are few changes to manage at each backup cycle and / or if there are not too many users to manage.
Conclusions
The use of Object Storage is very interesting in terms of retention management, as well as in terms of cost optimization. In the case of Microsoft Azure, the integration with the Archive component helps companies to reduce costs even more by adopting a long-term retention policy in an automated way.
#DBS